
Yusheng Dai
Hello 👋!
I am Yusheng Dai, and I recently joined Monash University in Australia to work with Prof. Jianfei Cai. Before that, I completed my Master’s program at University of Science and Technology of China (USTC) working with Prof. Jun Du and Prof. Chin-hui Lee. I obtained my Bachelor’s Degree in Cyber Engineering from Sichuan University in June 2022.
My research focuses on audio-visual modality generation and understanding. Specifically, recent work includes multi-conditional-based universal audio generation, Visual-Text to Speech Audio and Music (VT2SAM), which considers both semantic and temporal alignment. I am also interested in extending standard diffusion-based mel-spectrum generation to better approximate the complete real world, such as in long latent spaces (e.g., infinite-duration audio or panorama) or higher resolutions (up to 44.1kHz audio). Earlier, I focused on audio-visual speech recognition using talking-face videos in noisy, multi-speaker scenarios.
News
- [July 2025]: Our work on Timing Audio Generation benchmark —— AudioAtlas has been accepted by ACM MM 2025.
- [June 2025]: Our work on Long Audio and Panorama with Swap Latent Joint Diffusion has been accepted by ICCV 2025.
- [Nov. 2024]: Obtained National Scholarship at University of Science and Technology of China.
- [Oct. 2024]: Obtained Monash International Tuition Scholarship (MITS) and Monash Graduate Scholarship (MGS).
- [Feb. 2024]: One paper on the robustness of audio-visual speech recognition has been accepted to CVPR 2024.
- [Jan. 2024]: The extended paper of our self-driven work on financial time series prediction has been accepted by SDM 2024. Thanks to my co-authors for this unforgettable cooperation! Hopefully, this algorithm can help us make enough money for the future Mars trip :).
- [Dec. 2022]: Welcome to join our MISP2023 competition on speech enhancement task! Here is the baseline system.
- [Mar. 2023]: One paper on low-level audio-visual signal processing has been accepted by ICME 2023, which is the first paper in my graduate career. I have the opportunity to go to Australia! For sure, here is the code.
- [Dec. 2022]: Welcome to join our MISP2022 competition on speaker diarization and long-time AVSR task! Here is the baseline system.
- [Oct. 2022]: We have some ideas to firstly extend MAMMAL in financial data analysis and the paper is accepted by NeurIPS DistShift 2022 workshop.
- [Dec. 2021]: We release the largest Mandarin audio-visual dataset called MISP-AVSR. The dataset is recorded in TV rooms of home environments with multiple groups chatting simultaneously. Welcome to join our MISP2021 competition as the grand challenge of ICASSP! Here is the baseline system.
Selected Publications [ Google Scholar]
-
 ICCV
International Conference on Computer Vision (ICCV), 2025.
ICCV
International Conference on Computer Vision (ICCV), 2025. -
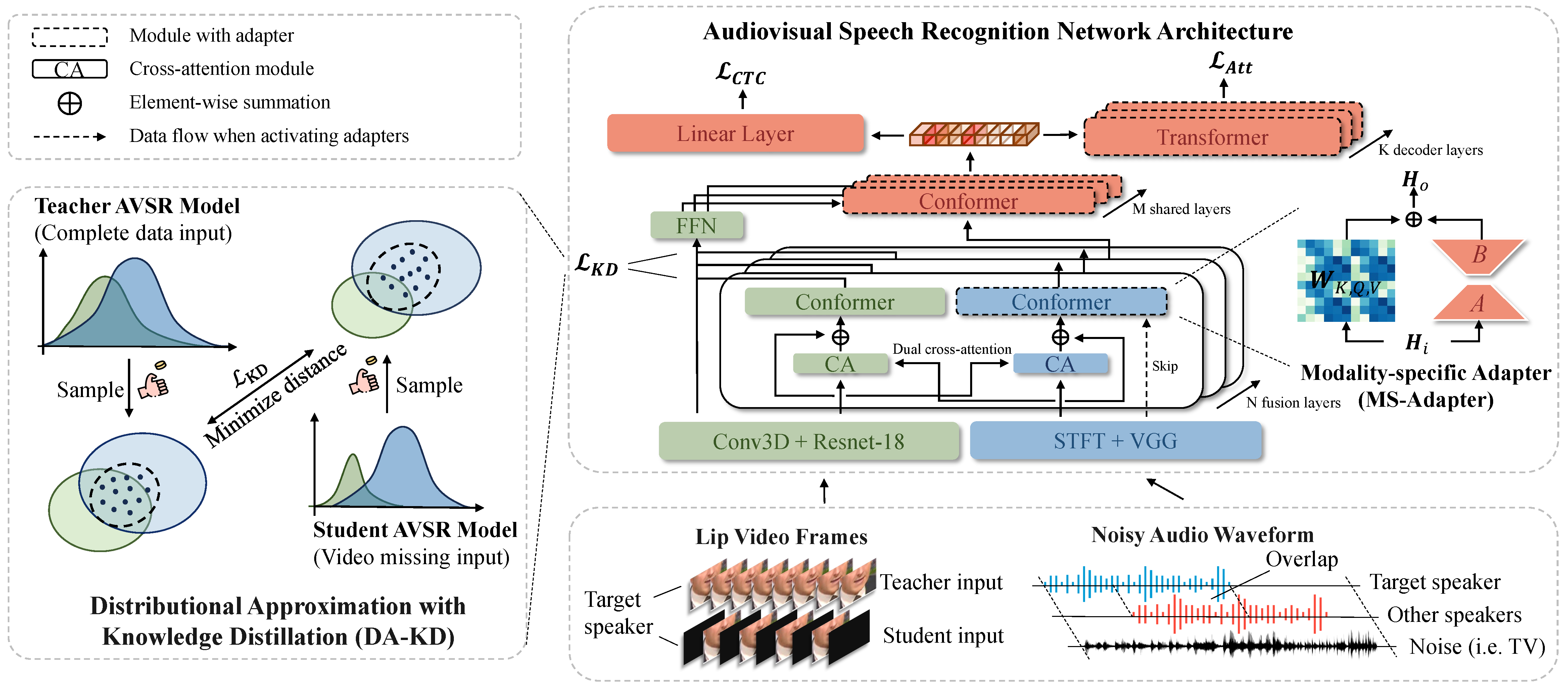 CVPR
IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR), 2024.
CVPR
IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR), 2024. -
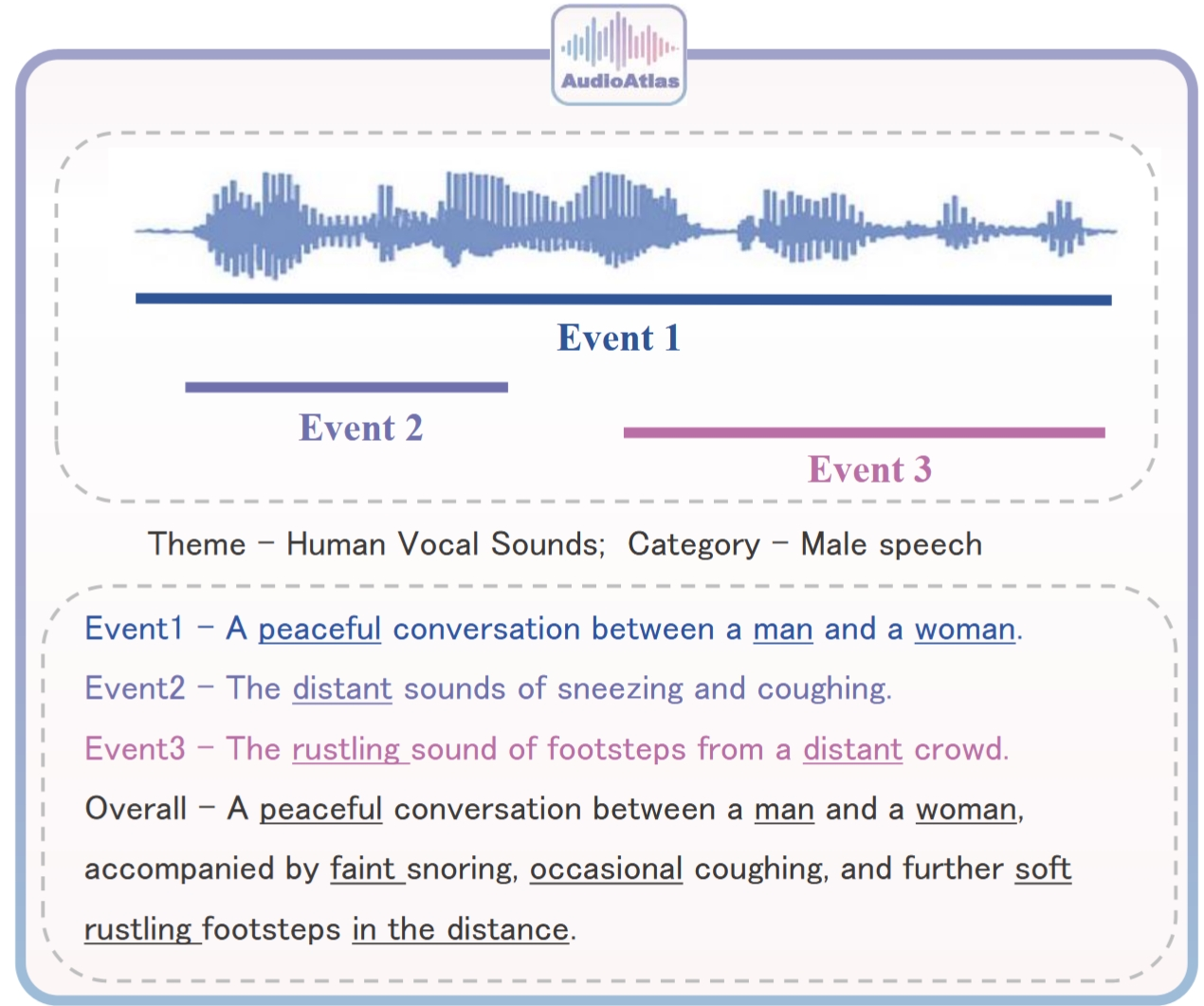 ACM MM
ACM International Conference on Multimedia (ACM MM), 2025.
ACM MM
ACM International Conference on Multimedia (ACM MM), 2025. -
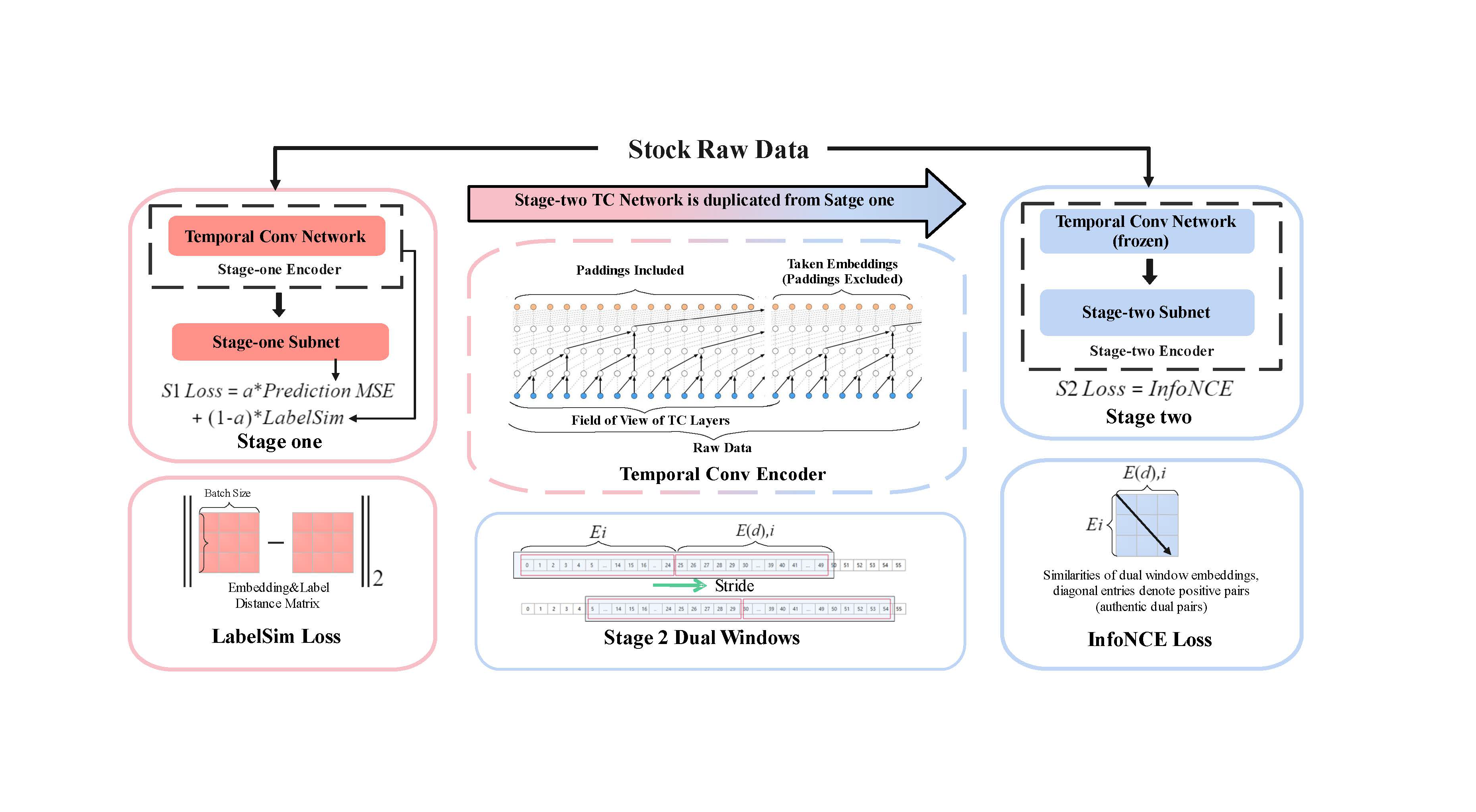 NeurIPS DistShift
Conference on Neural Information Processing Systems Workshop on Distribution Shifts (NeurIPS DistShift), 2022.
NeurIPS DistShift
Conference on Neural Information Processing Systems Workshop on Distribution Shifts (NeurIPS DistShift), 2022. -
 Electronics Letters
Electronics Letters
-
 Interspeech
In Proceedings of the Annual Conference of the International Speech Communication Association (Interspeech), 2022.
Interspeech
In Proceedings of the Annual Conference of the International Speech Communication Association (Interspeech), 2022.